Lexicon+TX: A Low-Cost, Flexible Framework for Multilingual Lexicon Construction
Motivation
Multilingual lexicons are important resources for many natural language processing (NLP), cross-lingual information retrieval and text mining applications. Since compiling multilingual lexicons manually from scratch is a time-consuming and labour-intensive undertaking, there have been many efforts to create them via automatic means. Most of these attempts require input lexical resources with rich content (e.g. semantic networks, domain codes, semantic categories) or large corpora. Such material is often unavailable and difficult to construct for under-resourced languages. In some cases, particularly for some ethnic languages, even unannotated corpora is still in the process of collection.
Objectives
The objective of my doctoral thesis project is therefore to propose a flexible framework for constructing multilingual lexicons using low-cost input and means, such that under-resourced languages can be rapidly connected to richer, more dominant languages. The framework should be flexible enough to allow initial construction with shallow data, with semantics and other deeper levels of information to be added in later stages. The constructed multilingual lexicon may then be used to extract new bilingual dictionaries, or used in a context-dependent lexical lookup module.
A study on existing multilingual lexicon projects revealed that design approaches may broadly be categorised as ‘deep’ or ‘shallow’, depending on whether a formal interlingual network was used for modelling translation equivalence. It was also identified that multilingual lexicons need to address some lexicographic phenomena like polysemy and diversification, lexical gaps and multiword-expressions (MWEs).
Framework Overview

The main components and research contributions of the Lexicon+TX framework are:
- A multilingual lexicon design based on a ‘shallow’ model of translational equivalence, so that volunteers without specialised linguistics background may be recruited to help improve and validate the multilingual lexicon.
- A multilingual lexicon construction methodology, the modified One-Time Inverse Consultation (OTIC), that requires only simple bilingual dictionaries as input, thereby alleviating the problem of resource scarcity.
- A method for extracting translation context knowledge from a bilingual comparable corpus using latent semantic indexing (LSI), such that the multilingual lexicon may provide context-dependent lexical lookup functions for other languages, including under-resourced ones.
- A flexible annotation schema, SSTC+Lexicon (SSTC+L), for aligning lexicon entries to their occurrences in texts for effective and tractable processing by computer systems. This schema is especially effective for annotating syntactically flexible multi-word expressions, as well as lexical gaps in bilingual corpus.
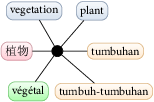
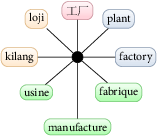
Lexicon+TX Multilingual Lexicon
A prototype multilingual lexicon, Lexicon+TX, containing six member languages i.e. English, Chinese, Malay, French, Thai and Iban (the last of which is an under-resourced language) has been constructed using only simple dictionaries, most of which are freely available for research or under open-source licences.
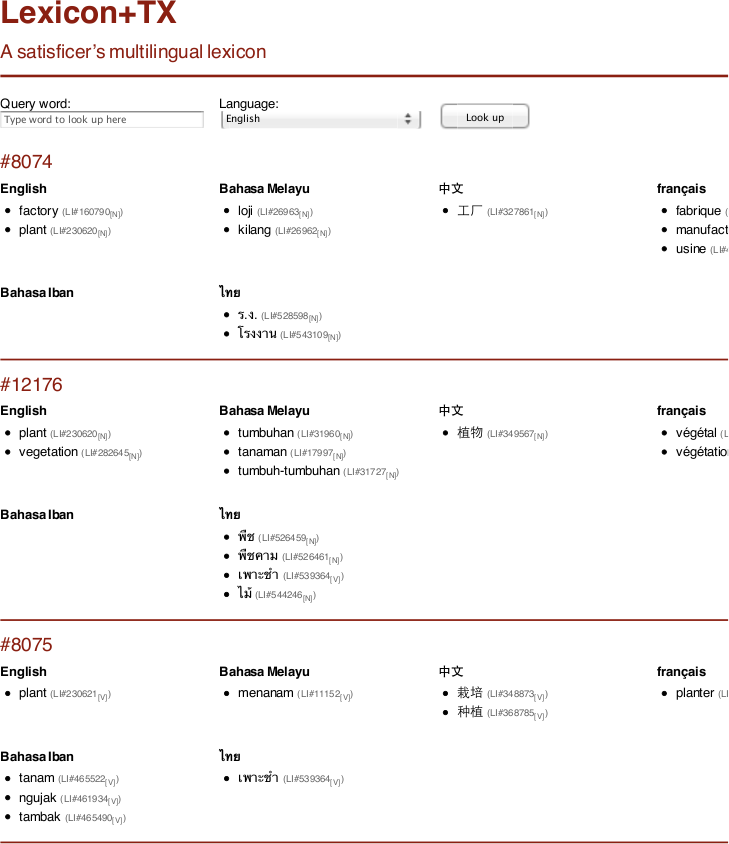
LexicalSelector Context-Dependent Lexical Lookup Tool
An accompanying context-dependent lexical lookup module has also been implemented in Java, and trained on an English—Malay bilingual corpus using Wikipedia articles. The lookup module works on all Lexicon+TX member languages, including Iban.


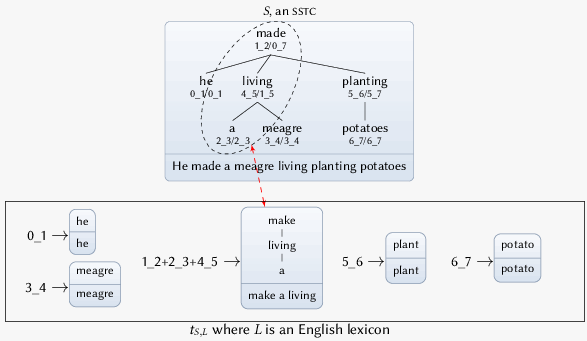
Annotating Lexical Item Occurrences in Text
The SSTC+L annotation schema is especially effective for annotating syntactically flexible multi-word expressions.
Related Publications
- Lim, L. T. (2013). Low-cost multilingual lexicon construction for under-resourced languages. PhD thesis. Faculty of Computing and Informatics, Multimedia University, Cyberjaya, Malaysia.
- Lim, L. T., Soon, L.-K., Lim, T. Y., Tang, E. K. & Ranaivo-Malançon, B. (Accepted). Lexicon+TX: rapid construction of a multilingual lexicon with under-resourced languages. Language Resources and Evaluation.
- Lim, L. T., Soon, L.-K., Lim, T. Y., Ranaivo-Malançon, B. & Tang, E. K. (2013). Context-dependent multilingual lexical lookup for under-resourced languages. [Paper] [Poster] Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (vol. 2, pp. 294—299). Sofia, Bulgaria.
- Lim, L. T., Ranaivo-Malançon, B. & Tang, E. K. (2011). Low cost construction of a multilingual lexicon from bilingual lists. Polibits, 43, 45–51.
- Lim, L. T., Ranaivo-Malançon, B. & Tang, E. K. (2011). Symbiosis between a multilingual lexicon and translation example banks. Procedia: Social and Behavioral Sciences, 27, 61–69.
- Lim, L. T. (2009, Dec.). Multilingual lexicons for machine translation. In Proceedings of the 11th International Conference on Information Integration and Web-based Applications & Services (iiWAS2009) Master and Doctoral Colloquium (MDC) (pp. 732—736). Kuala Lumpur, Malaysia.